Scientist recovers coronavirus gene sequences secretly deleted last year in Wuhan
과학자들은 작년에 우한에서 비밀리에 삭제된
코로나바이러스 유전자 염기서열을 복구한다.
By Jeanna Bryner - Live Science Editor-in-Chief 2 days ago
이틀 전 라이브 사이언스 편집국장 - Jeanna Briner
He finds 13 sequences from some of the earliest cases in Wuhan.
그는 우한의 초기 사례 중 일부에서 13개의
염기서열을 발견했다.
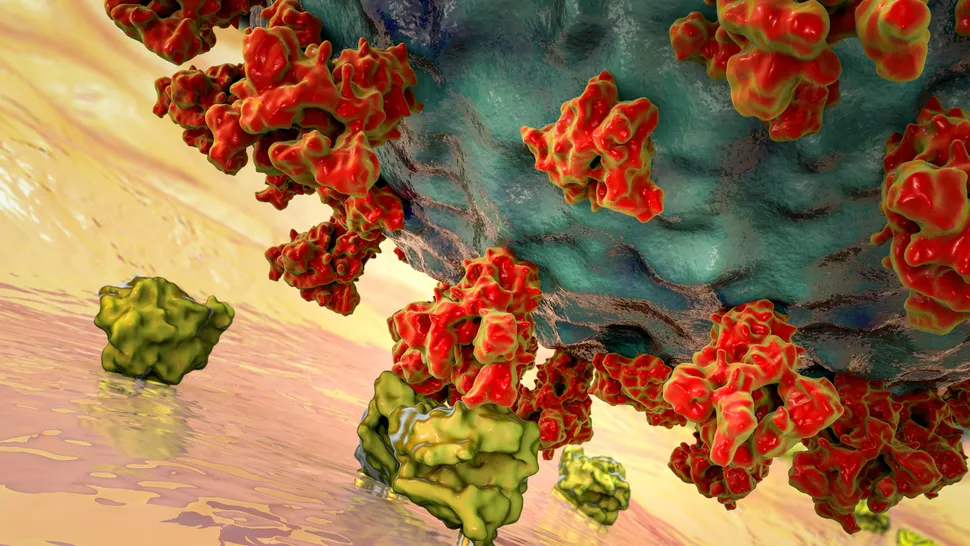
The SARS-CoV-2 virus invades human cells by attaching to ACE2 receptors on the surfaces of those cells. (Image credit: Shutterstock)
사스-CoV-2 바이러스는 사람들의 세포 표면의 ACE2 수용체에
달라붙어 인간 세포를 침범한다.
(이미지 크레딧: 셔터스톡)
Finding the origin story for SARS-CoV-2, the coronavirus responsible for nearly 3.9 million deaths worldwide, has been largely hampered by lack of access to information from China where cases first popped up.
전 세계적으로 거의 390만 명의 사망을 초래한 코로나바이러스인
사스-CoV-2의 기원을 밝혀낸 것은, 환자들이 처음 나타났던 중국
으로부터의 정보에 대한 접근 부족으로 인해 대부분 방해를 받아왔다.
Now, a researcher in Seattle has dug up deleted files from Google Cloud that reveal 13 partial genetic sequences for some of the earliest cases of COVID-19 in Wuhan, Carl Zimmer reported for The New York Times.
현재 시애틀의 한 연구원이 우한에서 발생한 초기 COVID-19
사건의 13가지의 부분적인 유전자 배열이 밝혀진 구글 클라우드
에서 삭제된 파일을 찾아냈다고 칼 짐머가 뉴욕타임스에 보도했다.
The sequences don't tip the scales toward or away from one of the many theories about how SARS-CoV-2 came to be — they do not suggest the virus leaked from a high-security lab in Wuhan, nor do they suggest a natural spillover event. But they do firm up the idea that the novel coronavirus was circulating earlier than the first major outbreak at a seafood market.
그 배열은 사스-CoV-2가 어떻게 생겨났는지에 대한 많은 이론들 중
하나와 비슷하거나 비슷하지 않은 그 눈금치의 첨단이 되지 못한다는--
그들은 바이러스가 우한에 있는 고도의 보안 실험실에서 유출되었다.
고 주장하지도 않고 자연적인 유출 사건을 제안하지도 않는다.
그러나 그들은 이 새로운 코로나바이러스가 수산물 시장에서 처음
발생한 주요 발병보다 더 일찍 나돌고있었다는 생각을 확고히 했다.
Related: 14 coronavirus myths busted by science
관련 내용:
과학에 의해 깨진 14개의 코로나바이러스 신화
In order to determine exactly how and where the virus originated, scientists need to find the so-called progenitor virus, the one from which all other strains descended. Until now, the earliest sequences are primarily those sampled from cases at the Huanan Seafood Market in Wuhan, which was initially thought to be where the novel coronavirus first emerged at the end of December 2019. However, cases from early December and as far back as November 2019 had no ties to the market, indicating pretty early in the pandemic that the virus emerged from another spot.
바이러스가 정확히 어떻게 어디서 발생했는지 알기 위해서 과학자들은
다른 모든 변종들이 유래한 소위 조상 바이러스를 찾아야 한다.
지금까지 가장 초기 염기서열은 신종코로나 바이러스가 주로 2019년
12월 말에 처음 출현한 것으로 생각되었던 우한의 화난 수산 시장에서
환자로부터 추출된 것이다.
그러나 12월 초와 2019년 11월까지의 사례들은 시장과 관련이 없었고,
이것은 유행병의 거의 초기에 다른 지점에서 바이러스가 출현했음을
보여준다.
There was one nagging issue with those first genetic sequences. Those from cases found at the market include three mutations that are missing in virus samples from cases that popped up weeks later outside of the market. The viruses missing those three mutations matched more closely with the coronaviruses found in horseshoe bats. Scientists are relatively certain that the novel coronavirus somehow emerged from bats, so it's logical to assume the progenitor would also be missing those mutations.
첫번째 유전자 배열에 대한 한가지 지속적인 문제가 있었다.
시장에서 발견된 사례들로는 몇 주 후 외부에서 튀어나온 사례에서 나온
바이러스 샘플에서 사라진 3가지 돌연변이를 포함한다 .
이 세 가지 돌연변이를 빠뜨린 바이러스는 관박쥐에서 발견되는 바이러스
와 더 밀접하게 일치했다.
과학자들은 이 새로운 코로나바이러스가 어떻게든 박쥐에게서 나왔다고
비교적 확신하고 있기 때문에, 그 조상 역시 이러한 돌연변이를 놓치고
있을 것이라고 추측하는 것이 논리적이다.
And now, Jesse Bloom of the Howard Hughes Medical Institute in Seattle has found the deleted sequences — likely some of the earliest samples — also were devoid of those mutations. (Bloom is the lead author in a letter published in May in the journal Science urging an unbiased investigation into the origins of the coronavirus, Live Science reported.)
그리고 지금 시애틀에 있는 하워드 휴즈 의학 연구소의 제시 블룸은
삭제된 결과들--아마도 초기 샘플들 중 일부도-- 이러한 돌연변이가
없다는 것을 발견했다.
(블룸은 코로나바이러스의 기원에 대한 공정한 조사를 촉구하며
지난 5월 사이언스지에 게재된 보고서의 주 저자이다.)
"They're three steps more similar to the bat coronaviruses than the viruses from the Huanan fish market," Bloom told The New York Times. This new data hints that the virus was circulating in Wuhan well before it showed up at the seafood market, Bloom said.
"그것들은 환난 어시장의 바이러스보다 박쥐의 코로나 바이러스와
세 단계 더 비슷합니다," 라고 블룸은 뉴욕타임스에 말했다.
이 새로운 데이터는 바이러스가 수산물 시장에 나타나기 훨씬 전에
우한에서 퍼지고 있었다는 것을 암시한다고 블룸은 말했다.
"This fact suggests that the market sequences, which are the primary focus of the genomic epidemiology in the joint WHO-China report ... are not representative of the viruses that were circulating in Wuhan in late December of 2019 and early January of 2020," Bloom wrote in his paper uploaded June 22 to the preprint database bioRxiv.
블룸은 6월 22일 인쇄 전 데이터베이스인 bioRxiv에 올린 논문에서
"이 사실은 WHO-China 공동 보고서에서 주로 게놈 역학에 초점을
맞춘 시장의 염기배열은 2019년 12월 말에서 2020년 1월 초에 우한
에서 나돌았던 바이러스를 대표하지 않음을 시사합니다" 라고 썼다.
According to Zimmer, about a year ago 241 genetic sequences from coronavirus patients had gone missing from an online database called Sequence Read Archive that's maintained by the National Institutes of Health (NIH).
짐머에 따르면, 약 1년 전 미국 국립 보건원에 의해 유지되고 있는 연속
읽기 보관소라는 온라인 데이터베이스로부터 코로나바이러스 환자들
의 유전자 배열 241개가 사라졌다고 한다.
Bloom noticed the missing sequences when he came across a spreadsheet in a study published in May 2020 in the journal PeerJ in which the authors list 241 genetic sequences of SARS-CoV-2 through the end of March 2020; the sequences were part of a Wuhan University project called PRJNA612766 and were supposedly uploaded to the Sequence Read Archive. He searched the archive database for the sequences and got the message "No items found," Bloom wrote in the bioRxiv paper, which has not been peer-reviewed.
블룸은 2020년 5월 발간된 피어제이 저널에 실린 연구 결과에서 누락된
스프레드시트를 발견했을 때 사라진 염기서열을 발견했는데, 이 연구결과에
저자들이 2020년 3월 말까지 사스-CoV-2의 241개 유전자 염기서열을
나열한 것이다.
이 염기서열은 PRJNA612766이라고 불리는 우한 대학 프로젝트의 일부
였으며, 아마도 연속 읽기 보관소에 업로드된 것으로 추정된다.
블룸은 그 염기서열 기록물 보관 데이터베이스를 검색했으나 블룸이 동료
검토가 이뤄지지 않은 바이오Rxiv 논문에 기록했던 "기록물을 찾을 수
없습니다" 라는 메시지만 받았다.
Related: 11 (sometimes) deadly diseases that hopped across species
관련내용: 종을 뛰어넘는 11가지 치명적인 질병
His sleuthing revealed that the deleted sequences had been collected by Aisu Fu and Renmin Hospital of Wuhan University, and a preprint of the research published from those sequences (referred to as Wang et al. 2020) suggested they came from nose swab samples from outpatients with suspected COVID-19 early in the epidemic.
그의 연구를 통해 삭제된 염기서열이 우한 대학의 아이수 푸와 런민 병원에
의해 수집되었다는 것이 밝혀졌고, 그 염기서열로부터 발표된 연구의 사전
인쇄물(Wang et al. 2020)은 이 염기서열의 초기 COVID-19 의심 외래 환자
들의 코 면봉 샘플에서 나온 것임을 시사했다.
Bloom couldn't find any explanation for why the sequences had been deleted, and his emails to both corresponding authors to inquire received no response.
블룸은 이 시퀀스가 삭제된 이유에 대한 설명을 찾을 수 없었고, 두 작가에게
문의하기 위해 보낸 이메일은 아무런 응답을 받지 못했다.
"There is no plausible scientific reason for the deletion: the sequences are perfectly concordant with the samples described in Wang et al. (2020a,b)," Bloom wrote in bioRxiv. "There are no corrections to the paper, the paper states human subjects approval was obtained, and the sequencing shows no evidence of plasmid or sample-to-sample contamination. It therefore seems likely the sequences were deleted to obscure their existence."
블룸은 bioRxiv에서 "이러한 과학적 삭제 이유는 없습니다. 그 순서가
Wang et al. (2020a,b)에서 설명한 샘플과 완벽하게 일치하기 때문입
니다." 라고 썼다.
"논문에 대한 정정 내용도 없고, 실험 대상자의 승인을 얻었다고 명시
되어 있으며, 염기서열 분석 결과 플라스미드 또는 샘플 간 오염의 증거
도 발견되지 않았습니다. 따라서 염기서열은 그들의 존재를 감추기
위해 삭제된 것 같습니다."
Bloom notes several limitations to his study, primarily that the sequences are only partial and include no information to give a clear date or place of collection — information crucial to tracing the virus back to its origin.
블룸은 연구의 몇 가지 제한 사항을 주요시하는데, 주로 그 염기서열은 부분
적일 뿐이며 --바이러스를 원점으로 추적하는 데 중요한 정보인 명확한
날짜나 수집 장소를 제공하기 위한-- 정보가 포함되어 있지 않다, 고 한다.
Regardless, Bloom thinks that looking more deeply at archived data from the NIH and other organizations — and piecing together the sequences — could help to paint a clearer picture of both the origin and early spread of SARS-CoV-2, all without needing on-the-ground studies in China.
그럼에도 불구하고, 블룸은 NIH와 다른 기관의 아카이브된 데이터를
더 깊이 들여다 보고, 그 염기서열을 종합해 보면, 중국에서 현장 연구가
필요 없이, 사스-CoV-2의 기원과 초기 확산 양쪽에 대한 더 명확한
그림을 그릴 수 있을 것이라고 생각한다.
Read more about the deleted sequences at The New York Times.
삭제된 염기서열에 대한 자세한 내용은 뉴욕 타임즈를 참조하십시오.
Originally published on Live Science.
라이브 사이언스에 원본으로 발간됨.

댓글 없음:
댓글 쓰기